Entangled Words: Using Tensor Networks to Build Smarter, Smaller Transformers
"Harnessing" = action-driven, powerful word.

Introduction — Why We Need a New Geometry for Language Models
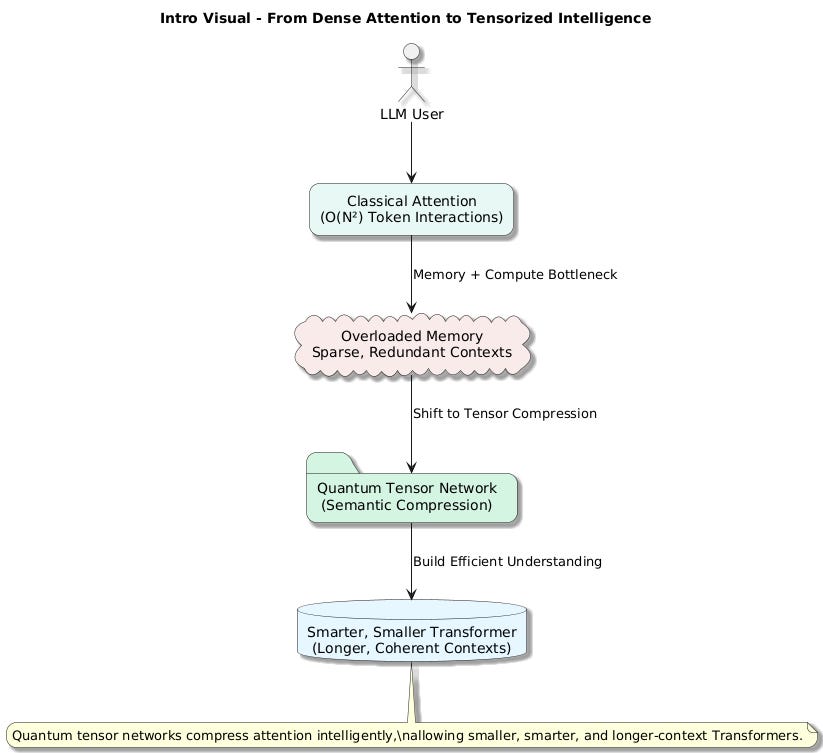
Large language models today are breathtakingly powerful — but also breathtakingly inefficient.
Despite billions of parameters and trillions of tokens, they suffer from:
Redundant token interactions
Burdensome memory footprints
Difficulty handling long contexts without degrading
At their core, LLMs repeatedly recompute all pairwise relations between tokens, even when many of those relations are weak, redundant, or structured.
Is there a better way?
Can we compress semantic relations intelligently, without losing crucial meaning?
The answer may lie in a surprising place:
Quantum tensor networks.
Originally invented to compress quantum states with long-range entanglements, tensor networks could offer a revolutionary new geometry for language understanding.
1. What is a Tensor Network? (A Gentle Introduction)
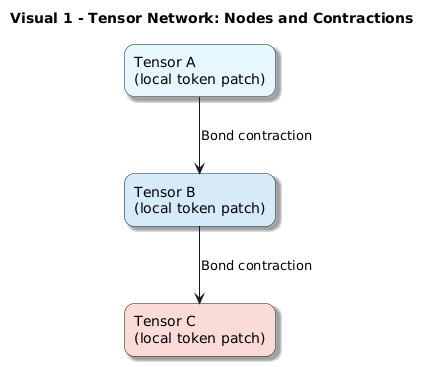
A tensor network is a mathematical structure that factorizes a giant multidimensional tensor into smaller, interconnected pieces.
Rather than storing the full, exponentially large tensor directly, we break it into parts:
Nodes = smaller tensors
Edges = contractions (summations) along shared dimensions
By choosing the right network topology, tensor networks can represent complex global structures efficiently and compactly.
Common examples include:
MPS (Matrix Product States): Linear chains of tensors
MERA (Multi-scale Entanglement Renormalization Ansatz): Tree-like hierarchies with long-range compression
PEPS (Projected Entangled Pair States): 2D grid tensor networks
In quantum physics, these architectures allow us to simulate systems that would otherwise require exponentially large memory.
In NLP, they could allow us to simulate token interactions without quadratic blowup.
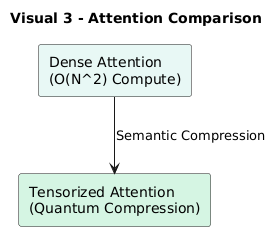
2. The Problem with Classical Attention
In a standard Transformer, every token attends to every other token:
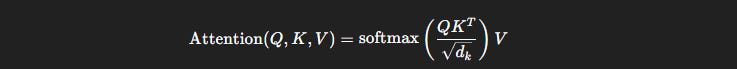
where Q, K, and V are query, key, and value matrices.
This results in O(N²) interactions for N tokens — expensive in time and memory.
Moreover, most token pairs don’t actually need fine-grained interactions:
Articles (“the”, “a”) and frequent function words
Distant, weakly-related concepts
Redundant sentence structures
Most semantic structure is sparse and hierarchical, not fully dense.
Tensor networks naturally exploit this hidden sparsity and hierarchy.
3. How Tensor Networks Compress Global Correlations
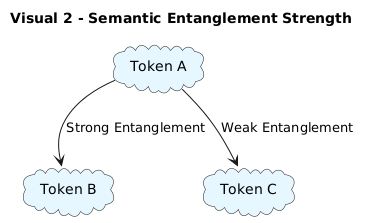
Imagine token embeddings not as isolated vectors, but as entangled pieces of a latent semantic manifold.
Some words are strongly entangled (e.g., “quantum” and “entanglement”).
Others are weakly entangled (e.g., “apple” and “philosophy”).
Rather than treating every interaction equally, tensor networks allocate representation power proportionally to entanglement.
Close, strong semantic bonds = heavily connected tensors
Distant, weak semantic links = compressed or ignored paths
Thus, the overall semantic structure of text can be compressed —
preserving long-range dependencies where needed, and pruning redundancy elsewhere.
This mirrors how MERA compresses long-distance quantum correlations without destroying local details.
4. Modeling Attention Layers with Tensor Networks
The idea is to replace full attention matrices with tensor network architectures.
Instead of computing:
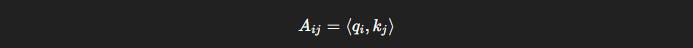
for every i,j pair directly,
we factorize the attention into a tensor network contraction sequence:
Tokens grouped into small local patches
Local attention computed inside patches
Higher-level tensors compress groupwise attention
Only a few global paths encode long-range interactions
Mathematically, this leads to an effective attention operator built from contracting a tensor network, rather than computing full QK^T.
Depending on the task, we could structure the network as:
MERA for deep, multiscale text (long articles, books)
MPS for linear conversations
PEPS for more complex semantic grids (e.g., storylines)
5. Mathematical Formulation: Tensorized Attention Layers
Formally, let’s define token embeddings x_i ∈ R^d.
Rather than storing all token pairings directly, we define local tensors:
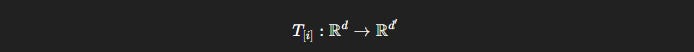
where each T_[i] interacts only with neighboring tensors.
The global semantic state Ψ is reconstructed via a contraction:

where “contract” means summing over shared latent dimensions.
The compression rate is controlled by:
Bond dimension
χ(controls entanglement)Tensor rank (controls local expressivity)
High-entropy sections (e.g., dense technical passages) require higher χ.
Simpler sections (e.g., greetings, closings) can be compressed heavily.
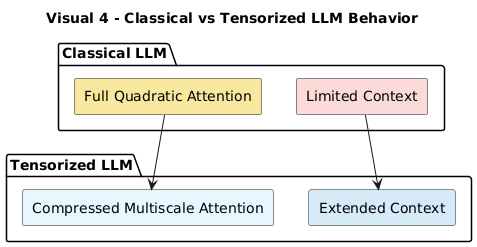
6. Applications: Why Tensor Networks Matter for LLMs
By using tensor networks inside attention, we could:
Dramatically reduce memory and compute costs from
O(N²)to nearlyO(N log N)Expand context windows into hundreds of thousands of tokens without linear slowdown
Preserve critical long-range dependencies intelligently (semantic entanglement aware)
Model multiscale text naturally: local wordplay vs global narrative arcs
Moreover, tensorized LLMs would be more interpretable — since tensor structures expose latent clusters and semantic pathways explicitly.
7. Future Work — Dynamic Tensor Architectures
Going further, we can imagine adaptive tensor networks:
Growing and contracting based on semantic need
Reshaping dynamically during decoding
Using quantum-inspired learning rules to optimize contraction order
Ultimately, LLMs could evolve into dynamic semantic machines,
navigating complex knowledge spaces with the minimal memory footprint necessary.
Quantum geometry and tensor networks may offer the blueprint.
Conclusion — Toward Smarter, Smaller, More Coherent AI
Language isn’t flat.
It’s entangled, hierarchical, and context-dependent.
To model it faithfully, we must move beyond naive dense matrices.
Tensor networks — born from quantum physics — may unlock a new generation of smarter, smaller, sharper Transformers.
The future of NLP might be not just larger —
but more geometrically beautiful.
You can follow me on Medium to read more: https://medium.com/@satyamcser
#NLP #QuantumAI #TensorNetworks #Transformers #SemanticCompression #MathematicalAI #satmis #LLM #ArtificialIntelligence