Deep Reinforcement Learning Foundations: Function Approximation & Experience Replay


The Story: When Tables Explode
Think back to our early adventures with RL:
In tabular Q-learning, we carefully updated a big spreadsheet of Q-values.
Every row = state, every column = action.
For toy worlds like Gridworld, this worked fine.
Now, picture applying the same method to Atari Breakout.
Each state is an image of 210×160 pixels with 128 colors.
That’s (128^210×160) possible states!
Even if we stored just a tiny fraction, the table would explode beyond comprehension.
This is the curse of dimensionality.
- Tables are too dumb for high-dimensional worlds.
Visual:

Step 1. Function Approximation
The idea: instead of storing each Q-value, we approximate Q with a parameterized function.
Linear Approximation
We define features ϕ(s, a) and parameters θ:
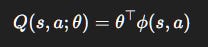
Learning = adjust θ to reduce TD error.
Deep Approximation
Use a neural network:
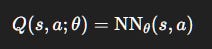
where N could be convolutional (for pixels) or MLPs (for features).
Objective Function
We minimize squared TD error:
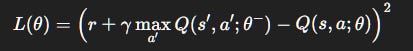
θ^-: weights of a target network (stabilization trick, explained later).
Visual:

Numerical Example 1: Linear Approximation Update
Suppose:
Features:
ϕ(s, a) = [s, a].Parameters:
θ= [0.2, 0.5].Input:
s= 2,a= 3.
Step 1: Predict Q

Step 2: Compute target
Say r = 2, γ = 0.9, target estimate = 2.5 (from next state).
Error = 2.5 − 1.9 = 0.6.
Step 3: Gradient update
Learning rate α = 0.1:

Interpretation: Parameters shift closer to making Q(2, 3) = 2.5.
Visual:

Step 2. The Danger of Neural Networks
Neural nets are powerful but risky in RL:
Correlated samples: consecutive frames are nearly identical, making training unstable.
Non-stationary targets: target depends on current
Q, which is constantly changing.Feedback loops: errors compound, causing divergence.
Imagine balancing on a moving boat while adjusting your stance using a wobbly mirror, that’s RL with raw neural nets.
Visual:

Step 3. Experience Replay
Solution: break correlations.
Store transitions (
s, a, r, s′) in a replay bufferD.Randomly sample minibatches for training.
Makes updates behave more like supervised learning with i.i.d. samples.
Loss with Replay Buffer
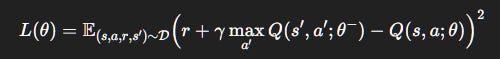
Replay also allows re-using past experiences, improving data efficiency.
Step 4. Target Networks
Problem: targets keep shifting because Q depends on itself.
Fix: use a frozen copy of the network for target evaluation.
Online network:
Q(s, a; θ).Target network:
Q(s, a; θ^−), updated only everyCsteps.
This gives stability by anchoring targets for a while.
Visual:

Numerical Example 2: Target Network Update
Suppose:
Online
Q:Q(s, a; θ)= 4.0.Reward:
r= 2.Discount:
γ= 0.9.Target network:
\max_{a’} Q(s’, a’; \theta^-)= 3.0.
Step 1: Compute target
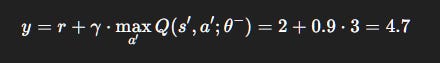
Step 2: TD error
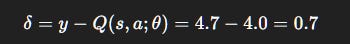
Step 3: Loss
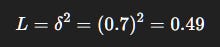
Interpretation: Online Q is pulled from 4.0 toward stable target 4.7. Without freezing, the target would chase itself and oscillate.
Visual:

Step 5. Why These Tricks Made Deep RL Possible
Together, function approximation, replay, and target networks created the Deep Q-Network (DQN) revolution:
2015: DeepMind’s Atari agent achieved human-level performance on dozens of games.
These ideas turned RL from toy examples into practical AI.
Without replay buffers and target networks, deep RL would remain unstable and unusable.
Special: Learn More in Learning to Learn: Reinforcement Learning Explained for Humans
Get it here:
Closing
Tables explode in large state spaces.
Function approximation replaces tables with models.
Experience replay breaks correlation and improves efficiency.
Target networks stabilize moving targets.
We solved two worked examples:
Linear approximation update (
θupdated from [0.2, 0.5] → [0.32, 0.68]).Target network TD error (loss = 0.49).
These concepts powered the leap to Deep RL, enabling agents to learn from pixels and continuous spaces.
Next in the roadmap → Deep Q-Network (DQN): putting it all together.
Follow and Share
You can follow me on Medium to read more: https://medium.com/@satyamcser
#ReinforcementLearning #DeepRL #DQN #ExperienceReplay #TargetNetworks #FunctionApproximation #NeuralNetworks #TDLearning #AIExplained #MachineLearning #MLMath #satmis